Security Log Lake: is this the future or is the current SIEM strategy enough?
As we continue to embrace digitalization the volume of security logs grows both in actual logs entries as well as sources of logs. How can we tackle this in a effectively way while keeping cost related to log management at a reasonable level?
Security Information and Event Management (SIEM) has been around for a long time where we traditionally have pumped all logs into the SIEM with the intent to effectively analyze the logs and find signs of unwanted behavior in our IT systems.
Advancements have been made to transform SIEM from searching for static patterns to work with more advanced User and Entity Behavior Analytics (UEBA).
Despite this move it can be found during forensic investigations that the logs needed to find the root cause of a breach may not be collected and/or stored long enough. It may be different root causes why such logs are not available, some of them related to the fact that ingesting large volumes of logs into SIEM drives a lot of cost. The cost issue often results in limiting to which logs to collect and how long to store them.
Big data and security logs
It is here where we in security can learn from the big data and BI space, where the concept of data lakes has been used for many years. The data lake is a repository of data that either is used for analytics or could be used in future use cases. Hence ensuring the availability of data that may not have a clear use case when collected but may be used for future use cases.
The same concept can be applied to logs, creating a security log lake that holds logs which could be of interest in the future. That future can either be that new SIEM/UEBA use cases, i.e. searches for unwanted behavior, is identified and can be applied to the data set. Or in the worst case a breach has occurred, and the data is needed to perform more in-depth analysis.
How to start a security log lake
A data lake is in its simplest forms a traditional storage with flat files, the same concept can be used for security log lake. This ensures that the data is kept secure but may present some additional work and delays when the data is to be used. Depending on the solutions used there are different ways to achieve this, if a traditional setup with syslog is used a syslog server can be added just for the Security Log Lake and flat files can be created per source and day. Using syslog-ng as an example the config would be in line with:
In a smaller environment this may be good enough to be able to work with the data during an incident. For larger environments the amount of data collected may pose additional problems when the data is to be parsed for later usage. Also, the usage of syslog as a transport may not suit all log sources and types of logs.
How to transport security logs
Several solutions to transport logs effectively have emerged, some tied directly to SIEM products while others are more generic. One of the more generic solutions are Fluentd and Fluentbit which can be used to route security logs to several destinations.
Our high-level overview shows that many different sources of input are supported, either directly or via Fluentbit or other agents. Fluentd acts as a central function to route the log data, and can also perform filtering if required, i.e. only send certain data to each destination. The destinations, outputs, can be multiple where many options are supported out of the box.
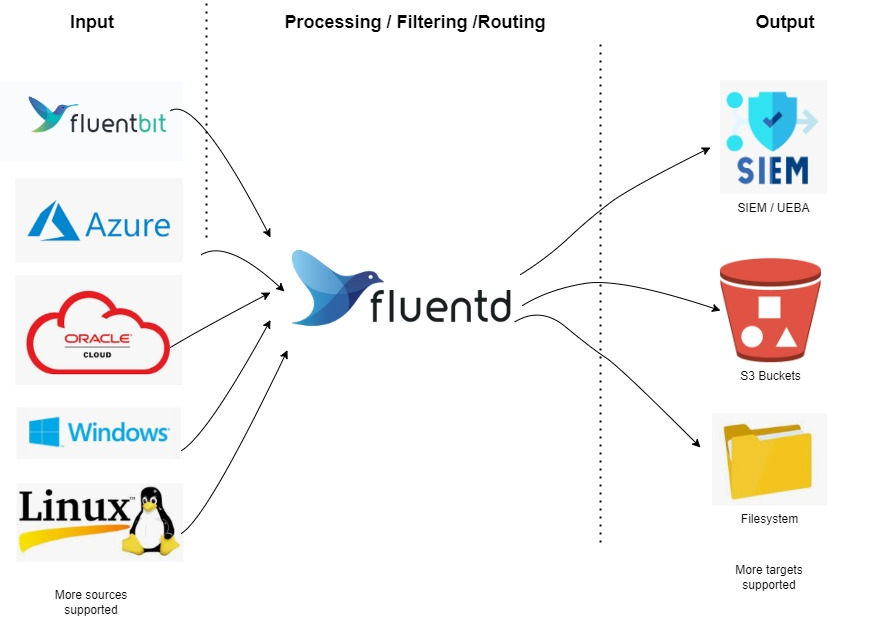
A central log collection function may also serve as an enabler, detaching the SIEM from the collection of logs. This opens up for a easier shift of SIEM platform if required. Routing can also be used to send certain logs to the infrastructure and/or applications operations teams log servers for their usage.
Fluentd is used as an example of one product, in your implementation you should evaluate different solutions and ensure to choose the most suitable for your requirements and technical environment.
Consolidate data
A large storage pool of data will be overwhelming when information shall be extracted, and as such there are strategies to apply when the data is stored in the security log lake. One of these strategies is to consolidate certain data in the logs, creating a more manageable amount of data to use as an index for your archive.
The example choosen is to show how to consolidate the IP addresses in logs and only store the unique IP addresses in an index. The concept can be applied to other fields in logs that are of interest when performing searches related to archived log data.
Below sample uses the awk command, normally included in Unix and Linux installations to parse the logfile to extract all unique IPv4 addresses.
awk '/^[0-9.]+[.][0-9]+$/{if(!a[$0]++)print $0}' RS="[ :/\n]" <logfile>
Indexing consolidated data
The output from the consolidated data needs to be retained to be useful in future searches. A first simple approach may be to store the data in flat files, naming convention could be the source file name and then append on that name, for example “logfile.ip”, “logfile.usernames” etc. This ensures a quick start of consolidating data.
A more long-term solution is to create a structured storage, preferable in database, where it is easy and fast to retrieve the information. Using a noSQL, for example OpenSearch, a simple document structure for these records could be expressed in the following JSON
This would result in a document for each IP in that logfile, another approach is to create a structure where each logfile has only one document and all relevant searchable consolidated data is included in this document structure.
Using consolidated data
In the event of a security incident the consolidated data can be used to identify all the log files that is of interest, in above example with IP addresses a quick search can be conducted in the index to identify all archived log files that contains the IP address of interest. As such only relevant log files is required to be retrieved from the security log lake and investigated.
Analysis of data from security log lake
A method for analysing the data is required, it may be that a manual search and analysis of the log data can be enough for the initial needs. Most often you will be left with too much data to manually analyse. Ingesting the archived data into the main SIEM can also be a method, this can however result in that SIEM raises alerts, gets overloaded and/or that analysts by mistake use old data for analysis. A good approach is to ingest the data in a separate instance where analysis can be performed and data removed afterwards. It is important that your design includes a method for performing this type of analysis.
How do you get started with security log lake?
The concepts in this blog article are quite generic and would serve as a base for the architecture of a security log lake. A good approach is to outline your requirements, set the architecture and then start building. Cegal consultants can help you in all these steps.
Cegal and Cybersecurity
Cegal consulting services helps our customers within the field of cybersecurity both with management and technical services. Contact us today to learn more about or offerings in this area.
I hope this was insightful 💚 Don't hesitate to reach out if you have any questions!